From Day 0 to 0day Chapter 2

MAPPING CODE TO ATTACK SURFACE
Once we know where we are, then the world becomes as narrow as a map.
When we don’t know, the world feels unlimited.
Liu Cixin, The Dark Forest
Introduction
Attack surface (the potential entry points to exploit a vulnerability) going often with the growing
of complexity of software.
The vulnerabilities to be introduced, as developers’ capacity to properly secure these feature is
limited and mistakes are inevitable when dealing with millions of lines of code.
Minor issues can be chained together into far more serious vulnerabilities.
For example :
- Microsoft Excel handles not only Excel workbook file format (
.xls,.xlsx,.xlsm,.xls) but also Symbolic Link (.slk), dBase (.dbf), Data Interchange Format (.dif), and more. And these are just file input vectors; you also have to worry about inter-process communication and other network vectors (Inter-Process Communication or IPC is a mechanism that allows processes to communicate. It helps processes synchronize their activities, share information, and avoid conflicts while accessing shared resources.).
For example, another process may control Excel via Component Object Model (COM) interfaces (These objects can be within a single process, in other processes, even on remote computers.), or it may fetch data from the internet via external data connections.
These are all potential sources for exploitable vulnerabilities .
The Internet
In the past, native and web applications lived in separate worlds:
- Native applications were compiled into machine code binaries that ran on specific devices and platforms.
- Web applications were mostly written in web development languages . They had vastly different attack surfaces and exploit vectors.
Web Client Vulnerabilities
Client-side vulnerabilities are especially for software running on native devices, such as desktop or mobile applications
Attack Vectors
The possible attack vectors vary depending on how the software parses the data.
The attack surface also depends on whether and to what extent an attacker controls the destination the software is connecting to.
These factors will affect the scope of your source code analysis
and the types of potential vulnerabilities you should look out for.
A man-in-the-middle (MITM) is often required for exploiting any vulnerability when software is running on a hardcoded URL This assumes some level of control over the network or device that the software is running on.
Exemple :
- Nintendo Switch - WebKit Code Execution:
CVE-2016-4657 web-kit vulnerability for ios 9.3, nintendo switch browser vulnerability ( i know whats running in your mind nintendo switch has no no browser, but when you need to use a wifi which needs to be conformed by logging in to the browser) a memory corruption in webkit .
To hijack this flow, an attacker could modify the Domain Name System (DNS) settings of the Switch (or the router it’s connected to), rerouting it to an attacker-controlled web server hosting a payload designed to exploit CVE-2016-4657.
Sources : Saelo , Phrack - Attacking Javascript Engines , ExploitDB PoC, Liveoverflow
- Reverse Engineering to Facebook Gameroom :
The Facebook Gameroom desktop application use the custom uniform resource identifier (URI) schemefbgame://gameid/it registered could be manipulated to cause the application to navigate to different pages onhttps://apps.facebook.comin its embedded Chromium-based browser.
By exploiting a few redirection gadgets on that domain, It was able to redirect back to the own attacker-controlled payload on a different domain that triggered a memory corruption vulnerability (CVE-2018-6056) on the outdated version off Chromium.
The combination of a local input vector (in this case, the custom URI scheme) and a web-based gadget chain (redirections inapps.facebook.com) is an increasingly common exploit pattern due to the growing prevalence of (often outdated) embedded browsers in desktop applications.
Source: Spaceracoon facebook gameroom RE
Identification and Classification
You can identify and classify web client functionality in code by searching for
web-related application programming interfaces (APIs) and library function
calls in the source code.
Developers often use libraries to simplify common
tasks like making web requests and parsing their responses.
For example, in previous exemple (about Facebook Gameroom) the researcher (Eugene Lim) determined that Facebook Gameroom included an
embedded browser because it imported CefSharp.dll, a .NET wrapper for
the Chromium Embedded Framework.
By tracing the usage of CefSharp
APIs in the decompiled C# code, he identified the most pertinent sections
that make up the web client attack surface of the application.
# example code to load and render a web page offscreen with CefSharp.
using System;
using CefSharp;
using CefSharp.OffScreen;
class Program
{
static void
(string[] args)
{
const string testUrl = "https://www.google.com/";
Cef.Initialize(new CefSettings());
var browser = new ChromiumWebBrowser();
browser.Load(testUrl); // 1
Console.ReadKey();
Cef.Shutdown();
}
}
# A simple CefSharp offscreen client
After any research we found that : ChromiumWebBrowser() refers to a class constructor used in CefSharp, an open-source framework that allows embedding a full-featured web browser into .NET applications (C# or VB.NET).
This is API call (//1) is a possible attack vector via a attacker-controlled url.
But it’s important to highlight an important point: When identifying the attack surface of software at
the macro level, the distinction between sources and sinks becomes blurred.
The key idea is that some functions, while not directly receiving data from a user (a source), use that data to perform an action (a sink).
Simple Example:
Imagine a program that takes a URL as input and displays the webpage.
- A user enters a URL like https://www.google.com/.
- The program uses a function like
browser.Load(user_input_url).- An attacker could enter a malicious URL like https://malicious-site.com/ which could lead to a server-side request forgery (SSRF) vulnerability or other attacks, where the server is tricked into making a request it shouldn’t.
The “blur” happens because a function can act as both.
Web Server Vulnerabilities
Web server or client containing a lot of vulnerabilities, and all of devices when it use it also, like Iot devices.
> Web Frameworks
Web application framework (WAF) is a software framework that is designed to support the development of web applications including web services, web resources, and web APIs.
Many web frameworks provide libraries for database access, templating frameworks, and session management, and they often promote code reuse.
Source : Web Framework
Consider this piece of code, which is a Node.js web server that exposes a few routes using the standard http library.
httpserver.js
const http = require('http');
const server = http.createServer((req, res) => {
res.statusCode = 200;
if (req.method === 'GET') { //1
if (req.url === '/') {
return res.end('index');
}
if (req.url === '/items') {
return res.end('read all items');
}
if (req.url.startsWith('/items/')) { //2
const id = req.url.split('/')[2];
return res.end(`read item ${id}`);
}
} else if (req.method === 'POST') {
if (req.url === '/items') {
return res.end('create an item');
}
}
res.statusCode = 404;
return res.end();
});
server.listen(8080, () => {
console.log('Server running at http://localhost:8080/');
});
A vanilla Node.js web server
- It’s difficulties of maintaining the code of large web applications without a web framework
- Distinguishing between
GETandPOSTroutes relies on clumsy nested conditional statements (//1), while fragile string operations are used to extract path parameters likeuserId(//2).
Now compare it to another Framework (Express)
expressserver.js
const express = require('express');
const app = express();
const itemsRouter = express.Router();
itemsRouter.get('/', (req, res) => { //1
res.send('read all items');
});
itemsRouter.post('/', (req, res) => {
res.send('create an item');
});
itemsRouter.get('/:id', (req, res) => {
const { id } = req.params; //2
res.send(`read item ${id}`);
});
app.get('/', (req, res) => {
res.send('index');
});
app.use('/items', itemsRouter);
app.listen(8080, () => {
console.log('Server running at http://localhost:8080/');
});
A web server built on the Express framework
Not only does Express do the same thing with less code, it also abstracts
away common tasks like checking the request method (//1), extracting path
parameters (//2), and handling nonexistent routes.
Web frameworks create opportunities to refactor code, such as moving
nested routes under /items to another file. This makes the code easier to
read both for developers and for you, the aspiring vulnerability researcher.
> The Model–View–Controller Architecture
One common pattern among web frameworks is the Model–View–Controller
(MVC) architecture, which separates the code into three main groups.
Familiarity with this pattern will help you quickly analyze frameworks, understand
the flow of data through sources and sinks, and focus on the critical business logic that is most likely to contain vulnerabilities instead of getting caught up
in irrelevant code.
The MVC architecture comprises three parts:
- Model Handles the “business logic”, such as data structures.
- View Handles the user interface, such as layouts and templates.
- Controller Handles the control flow from requests to relevant model and view components.
Spring MVC (a Java web framework) in were we converted a previous node app.
ItemController.java
@Controller
@RequestMapping("/items") //1
public class ItemController {
private final ItemService itemService;
@Autowired
public ItemController(ItemService itemService) {
this.itemService = itemService;
}
@RequestMapping(method = RequestMethod.GET)
public Map<String, Item> readAllItems() {
return itemService.getAllItems();
}
@RequestMapping(method = RequestMethod.POST)
public String createItem(ItemForm item) { //2
itemService.createItem(item);
return "redirect:/items";
}
@RequestMapping(value = "/{id}", method = RequestMethod.GET)
public Map<String, Item> readItemForId( @PathVariable Int id, Model model) {
return itemService.getItemById(id);
}
}
A partial controller code snippet for Spring MVC
When you read the code it difficult to understand her functions unless you’re familiar with the framework’s conventions.
Like
@Autowiredfor know her role it’s important to read the springs boot documentation, and after reading we read that it’s used to enables automatic dependency injection.
This annotation can be placed on a constructor, a method or directly on an attribute.
The Spring Framework will search for the bean in the application context whose type is applicable to each constructor parameter, method parameter or attribute.In (
//2), note the functioncreateItemreturnsredirect:/items. The redirect: prefix indicates that the route should redirect to the URL that comes after it, which in this case is/items.But any function or line are simple.
By exemple it’s still fairly obvious that the@RequestMappingannotation maps a handler method to a particular request route (GET,POST) . (//1)
Specially for object-oriented programming languages, you can encounter a controller who can inherits of methods and route of another controller (who often is declared in another file).
ThingController.java
@Controller
@RequestMapping("/things")
public class ThingController extends ItemController { //1
@RequestMapping(value = "/price", method = RequestMethod.GET) //2
public ModelAndView getPrice() {
// Controller code
}
}
An extended controller class
/things/priceroute handler (//2), this controller inherits the previous routes and methods fromItemController
> Unknown or Unfamiliar Frameworks
To effectively analyze web server code regardless of the framework used, focus on common routing and controller logic that all web applications must implement.
- First, identify how the code handles the basic building blocks of an HTTP request.
Here’s a simple example of what such a request might look like:
POST /items HTTP/1.1
Host: localhost
Content-Type: application/json
{
"name": "Apple",
"price": 1
}
The application needs to parse the following components:
Request method :
GETorPOSTrequest ? Grepping forGETorPOSTmight yield insights or a simple string comparison or more complex decorators like@GetMapping.URI : To locate routes quickly in a web application codebase, look for URI-like strings. If you have a working instance of the application, try matching the behavior you observe at a particular route with the code that handles that route .
Applications often handle routes declaratively, such asapp.get('/items')instead ofif (req.url === '/items').
Understanding the declarative convention is key. Some frameworks, like Ruby on Rails, even centralize the routing logic in specific files, such asconfig/routes.rb.Headers : Does the application check specific headers? Search for common headers like
OriginorContent-Type, Check all things about CORS and SOP .Parameters : How does the code extract parameters from a request? Other than the request URI, this is one of the most common sources of external input. Parameters can come from the HTTP request body (like the
JSONcontent in the example request), the query string, or within the path.
Next, identify how the code handles sending HTTP responses.
For example, after creating the item specified in the example request and adding it to the database, the web application could send:
HTTP/1.1 201 Created
Content-Type: application/json
Cache-Control: no-cache
{
"id": 1337,
"name": "Apple",
"price": 1
}
Focus on the building blocks of the HTTP response and map each of them to the code that appears to handle them. With this approach, you can intuitively work out the patterns of any framework to sufficiently map out the web attack surface based on reachable routes. You can also save a lot of time and effort by reading the documentation, if any is available, of the particular framework the application uses.
> Nontraditional Web Attack Surfaces
HTTP endpoints is not the only attack surface that can be used in software application context.
It may use protocols or formats like Web Distributed Authoring and
Versioning (WebDAV) or Really Simple Syndication (RSS) that build upon
or extend HTTP or other web-related protocols, such as WebSocket, Web
Real-Time Communication (WebRTC), and many more.
This means you should think beyond traditional web attack vectors.
Additionally, a web attack surface doesn’t mean you should look only for web vulnerabilities like SQL injection.
For example, at Pwn2Own Tokyo 2019, the security researcher known as “d4rkn3ss” exploited a
classic heap overflow vulnerability in the httpd web service of the NETGEAR Nighthawk R6700v3 router
Due to the limited compute and storage available on smart devices, it’s actually quite rare to find fully fledged web frameworks running on these devices.
Instead, you’re more likely to find compiled binaries that include both the web server and application logic.
This increases the possibility of
discovering classic non-web vulnerabilities like memory corruption even in
the web components.
It also means that your approach toward analyzing the
web attack surface of firmware will involve binary analysis techniques like
reverse engineering rather than source code analysis.
Some applications may spin up temporary web servers for inter-process communication. Software sometimes requires users to sign in via the browser as part of an OAuth flow. Exemple :
The GitHub command line interface (CLI) tool can trigger a web app OAuth
login flow via the github.com/cli/oauth package, which starts a local HTTP
server before opening a web browser to the initial OAuth web URL.
oauth_webapp.go
// 2024 GitHub, Inc.
package oauth
import (
"context"
"fmt"
"net/http"
"github.com/cli/browser"
"github.com/cli/oauth/api"
"github.com/cli/oauth/webapp"
)
// WebAppFlow starts a local HTTP server, opens the web browser to initiate the OAuth Web application
// flow, blocks until the user completes authorization and is redirected back, and returns the access token.
func (oa *Flow) WebAppFlow() (*api.AccessToken, error) {
host := oa.Host
if host == nil {
parsedHost, err := NewGitHubHost("https://" + oa.Hostname)
if err != nil {
return nil, fmt.Errorf("error parsing the hostname '%s': %w", oa.Hostname, err)
}
host = parsedHost
}
flow, err := webapp.InitFlow()
if err != nil {
return nil, err
}
params := webapp.BrowserParams{
ClientID: oa.ClientID,
RedirectURI: oa.CallbackURI, //1
Scopes: oa.Scopes,
Audience: oa.Audience,
AllowSignup: true,
}
browserURL, err := flow.BrowserURL(host.AuthorizeURL, params)
if err != nil {
return nil, err
}
go func() {
_ = flow.StartServer(oa.WriteSuccessHTML)
}()
browseURL := oa.BrowseURL
if browseURL == nil {
browseURL = browser.OpenURL
}
err = browseURL(browserURL)
if err != nil {
return nil, fmt.Errorf("error opening the web browser: %w", err)
}
httpClient := oa.HTTPClient
if httpClient == nil {
httpClient = http.DefaultClient
}
return flow.Wait(context.TODO(), httpClient, host.TokenURL, webapp.WaitOptions{ //2
ClientSecret: oa.ClientSecret,
})
}
After the user has successfully authenticated in the browser, the flow
redirects to the callback URL (//1) at the local HTTP server with the temporary authorization code and state.
The program then uses an HTTP client (//2) to make a POST request to the GitHub OAuth service’s token endpoint and
exchanges the authorization code for an access token.
In summary, the web attack surface covers a large variety of functionality, from clients to servers.
Network Protocols
Software can use many other network protocols than HTTP to communicate over networks.
The Transmission Control Protocol/Internet Protocol (TCP/IP) model organizes the communication protocols between systems in four layers:
Application Handles communication between applications (for example, HTTP, DNS, and FTP)
Transport Handles communication between hosts (TCP and UDP)
Internet Handles communication between networks (IP and ICMP)
Link Handles communication between physical devices (MAC)
Most software defers the handling of data at the lower layers to operating system APIs or standard libraries; discovering a vulnerability at these levels will create an extensive impact.
The majority of code you will encounter deals with the application layer,
such as the dhcp6relay server in SONiC (see Chapter 1). Since SONiC is built
to run on networking devices like switches, it’s a useful reference for mapping a software’s network protocol attack surface.
To identify potential network protocol attack vectors, start with the most
basic API calls: opening a network socket, listening to it, and receiving data.
Exemple :
“The Inter-Chassis Communication Protocol (ICCP) server initialization code”
/* Server socket initialization */
void scheduler_server_sock_init()
{
int optval = 1;
struct System* sys = NULL;
struct sockaddr_in src_addr;
if ((sys = system_get_instance()) == NULL)
return;
sys->server_fd = socket(PF_INET, SOCK_STREAM, 0); //1
bzero(&(src_addr), sizeof(src_addr));
src_addr.sin_family = PF_INET;
src_addr.sin_port = htons(ICCP_TCP_PORT); //2
src_addr.sin_addr.s_addr = INADDR_ANY; //3
--snip--
if (bind(sys->server_fd, (struct sockaddr*)&(src_addr), sizeof(src_addr)) < 0)
{
ICCPD_LOG_INFO(__FUNCTION__, "Bind socket failed. Error");
return;
}
The
[iccpd]server initialization code
- (
//1) :PF_INETrefer to IPV4 internet protocol, the next argument,SOCK_STREAMdefine the socket type (in this case is TCP) - (
//2) : The next line specify that socket use open portICCP_TCP_PORT(8888) who is defined in iccp_github_code - (
//3) : YOu can see that port is opened onINADDR_ANY, means that IP addresses associated with the system running the program.
The RFC (Request for Comments) documented any of standart protocol like tcp/ip, iccpd, etc…,
they are published by IETF (Internet Engineering Task Force). Their role is to describes the design and implementation of the protocol.
Read RFC can be a starting point when you targeting a software who implement the specific protocols
Often when the protocol is proprietary niche enough to require a tailor-made approch, the developpers can write her own custom implementation , who will surely less tested than open source protocols.
When reviewing code for a protocol, focus on two main features: the data structures and the procedures.
Data Structures
The data structures define how data is formatted and parsed in a network protocol.
- Exemple:
When you checkAgentX(Agent Extensibility Protocol) who is a networking protocol that enables a single SNMP master agent to manage multiple subagents
It was inplemented on sonic-snmpagent and documented in RFC 2741
The “Protocol Definition” section defines the AgentX protocol data unit (PDU) header.
6. Protocol Definitions
6.1. AgentX PDU Header
The AgentX PDU header is a fixed-format, 20-octet structure:
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| h.version | h.type | h.flags | <reserved> |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| h.sessionID |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| h.transactionID |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| h.packetID |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| h.payload_length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
An AgentX PDU header contains the following fields
The maintainer define a PDUHeaderTags class with a from_bytes :
sonic-snmpagent/src/ax_interface/pdu.py
class PDUHeaderTags(namedtuple('_PDUHeaderTags', ('version', 'type_',
'flags', 'reserved'))):
--snip--
@classmethod
def from_bytes(cls, byte_string):
return cls(
*struct.unpack('!BBBB', byte_string[:4])
)
Here is use !BBBB , mean that the bytes or octet should be interpreted in network byte order (big-endian) as four 1-byte unsigned chars.
The PDUHeaderTags instance respect the descriptions in the RFC, if the differences between the implementation and
of data stuctures (in the code) and the expected format required the vulnerabilities can occurs.
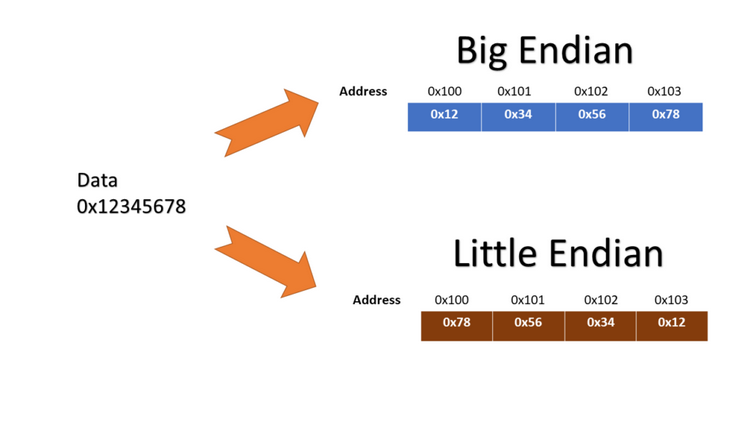
Ex :
In dhcpv6relay protocol implentation the option->option_length variable is parsed like a unsigned 16 bit integer (short type) who normaly have 65635 for maximum value.
before using it as number of bytes to copy into a fixed buffer of size 4096.
Procedures
A network protocol’s procedures define the rules and conventions of communication. These procedures include the expected order and actions taken by clients or servers.
When a data structures vulnerability lead to memory corruption issues, procedures problems do to higher-level business logic
such as authentication and authorization.
Knowing what constitutes a security boundary in a network protocol is necessary to correctly identify a business logic vulnerability.
Exemple of procedures :
- Handshaking: Initially exchanging messages in order to establish communication.
- Session management: Tracking individual sessions between the two entities.
- State management: Controlling the state of an individual session.
- Flow control: Managing the rate and order of data transmission.
- Error handling: Performing recovery or termination from invalid data.
- Encryption: Ensuring the privacy, authenticity, and integrity of communication.
- Session termination: Performing teardown and cleanup of the session in an orderly manner.
YOu can see by example of procedures describes in any rfc like rfc 2741 in section 7 (Elements of Pro- cedure.)
Local Attack Surface
Network Protocols like (TCP, UDP, SCTP) deal with communication between different machines (over the internet or local network).
When program or different part of the same program running on your computer IPC is the way these different programs can talk to each other and share information
on that one computer. IPC can happen between different processes or between threads within the same process.
Network protocols are for computers talking to other computers, while IPC is for programs talking to each other on the same computer.
AgentX can operate over the network and via IPC.
the attacker’s perspective, network transport protocols expose
a remote attack vector, while local transport protocols expose a (surprise!) local attack vector.
Why ? Because AgentX subagents to communicate with the master agent on the same host, RFC 2741 suggests local mechanisms such as shared memory,
named pipes, and sockets. This opens up a whole new attack surface for the
same protocol.
> Files in Inter-Process Communication
From sockets to devices, developers can expose many input/output resources using files to provide a common set of channels to work with.
When you IPC file exchange or file to exchange data between two process, the disk I/O is required for some action.
One exemple for this is to use lock files who indicates that a another process used this file, it can help to
prevent that multiple instance of the same file was running.
Real exemple is when you use editor like vim in two different terminal to modify a file, it show you a warning
showing you that another process already used this file (but here vim used .swap for temporary save data).
- Real life example: Exploiting a Hardcoded Path in Apport
One implementation of lock files led to an interesting privilege escalation vulnerability
(CVE-2020-8831) in Ubuntu via the Apport program.
The code causing this vulnerability lay in the check_lock,
function.
def check_lock():
'''Abort if another instance of apport is already running.
This avoids bringing down the system to its knees if there is a series of
crashes.'''
# create lock file directory
try:
os.mkdir("/var/lock/apport", mode=0o744) //1
except FileExistsError:
pass
# create a lock file
try:
fd = os.open("/var/lock/apport/lock", os.O_WRONLY | os.O_CREAT | os.O_NOFOLLOW) //2
except OSError as e:
error_log('cannot create lock file (uid %i): %s' % (os.getuid(), str(e)))
sys.exit(1)
def error_running(*args):
error_log('another apport instance is already running, aborting')
sys.exit(1)
original_handler = signal.signal(signal.SIGALRM, error_running)
signal.alarm(30) # timeout after that many seconds
try:
fcntl.lockf(fd, fcntl.LOCK_EX) //3
except IOError:
error_running()
finally:
signal.alarm(0)
signal.signal(signal.SIGALRM, original_handler)
- In
check_lockfunction the lock file in create if doesn’t exit (//1). - After it trying to acquire a lock file using a POSIX compliant API call who allow developers to implement lock files
in a more standized way. (
//3). O_NOFOLLOW: Inman 2 openit describe that “If the trailing component (i.e., basename) of pathname is a symbolic link, then the open fails, with the errorELOOP. Symbolic links in earlier components of the pathname will still be followed.” So with the hardcoded path/var/lock/apport/lockwho havelocklike basename, an attacker could use a symlink to redirect the program to read from or write to a different destination that the program has access to.
This is the problem: if any other component in /var/lock/apport/lock
other than lock is a symlink, Apport will still happily follow it. In the case of
Ubuntu, /var/lock is a symlink to /run/lock, which is readable and writable by
all users. As such, an attacker can create a symlink at /var/lock/apport pointing
to any other directory, and if Apport runs afterward, it will create a lock
file in the attacker-controlled destination.
> Sockets
A socket is an endpoint that allows communication between processes. It a one of the more common IPC channels and hence present a rich source of potential attack vectors.
Unix OS support Unix domain sockets (UDSs), a local variant (TCP, UDP, SCTP), but UDS don’t take care of protocol layer and run fast.
The socket respect the “everything is file” Unix philosophy so expose a UDSs in a filesystem pathname can lead to namespaces hijacking
or access control due to inappropriate file permissions.
Ex : A CVE-2022-21950 was a vulnerability in Canna, a Japanese Kana–Kanji
server, that arose from the hardcoded directory /tmp/.iroha_unix containing
the UDS used by Canna in openSUSE OS.
> Named Pipes
Named pipes are another means by which processes can communicate using a file-like paradigm. However, on Windows, named pipes have their own access control model separate from the default filesystem, creating an additional layer of potential authorization issues.
Take, for example, a high-privileged program that creates a named pipe
server and client for IPC. If a low-privileged attacker creates the named pipe
server before the program does, it could potentially intercept messages from
the client.
Worse, if the client makes use of the server’s responses to execute
actions such as running commands, it could lead to privilege escalation.
This was the case for CVE-2022-21893, a privilege escalation exploit in Windows Remote Desktop
Mapping Code to Attack Surface Services (RDS) that allowed an attacker to intercept the messages of RDS
named pipe IPC.
> Other IPC Methods
The number of IPC methods is constantly growing as operating systems and
third-party software add features. The following is a nonexhaustive list:
- Shared memory
- System signal
- Message queue
- Memory-mapped file
- Remote procedure call
- Component Object Model (COM, Windows only)
- Dynamic Data Exchange (DDE, Windows only)
- Clipboard
- D-Bus (Linux only)
- MailSlot (Windows only)
Developers use these APIs in creative (and potentially insecure) ways.
File Formats
Almost all software needs to handle files. From newline-delimited configuration files to video clips, we encode data in a variety of formats. Like protocols, file formats require software to parse data structures in a standard manner.
Many file formats are documented in RFCs, but proprietary or older
formats may require more digging.
For example, file formats are often roughly divided into three parts:
- Header: Appears at the start of the file and usually begins with a set of unique bytes so software can identify the file format.
- Body: Contains the main data associated with the format, often grouped into chunks for software to parse easily.
- Footer: Contains additional metadata, such as checksums to ensure data integrity.
Other formats diverge even further from the header-body-footer pattern, such as directory-based formats, which organize data into multiplefiles within a directory structure.
For example, Microsoft Office documents (such as .docx and .pptx files) are essentially ZIP containing
resource and metadata files such as XML documents, images, and so on.
> Type–Length–Value
The type–length–value (TLV) pattern occurs in both protocols and file formats. We use TLV for chunked data in the body because its structure allows
a parser to easily identify and consume chunks of variable length.
> Directory-Based
A significant subset of file formats are directory-based, meaning the file is actually a wrapper around many other files.
Like ZIP, DEB .
Typically, directory-based formats
require a manifest (manifest.xml) that contains additional metadata about the rest of the
files, including where they’re located. This pattern tends to expose two types
of vulnerabilities, related to file traversal and child format.
- File traversal occurs if the software insecurely parses the directory data. A parser that trusts such a value could extract files into dangerous locations, such as cron job folders or application working directories.
- Child format–related vulnerabilities occur because developers tend to focus on the parent directory–based format and delegate handling child file formats to external libraries, which may not parse securely by default.
Sometimes, both types of vulnerabilities occur in the same software. Example of vuln
Custom Fields
File formats often include reserved bytes or extendable fields that allow developers to add custom functionality. Sometimes, developers jerry-rig custom fields by parsing data differently from how a standard defines it. Thus, to indicate a stylesheet located at main.css, an HTML document could include the following element:
<link href="main.css" rel="stylesheet">
However, the WeasyPrint HTML-to-PDF conversion engine extends the function of <link> by supporting a custom attachment
value for rel that doesn’t appear in the HTML standard. By using this value,
a developer can include local files as attachments to the output PDF:
<link href="file:///etc/passwd" rel="attachment">
This is a feature, not a vulnerability in itself, but a developer that uses WeasyPrint without accounting for this behavior could introduce a vulnerability in their software.